
In order to trigger alerts when credentials of break-glass users are used, organizations can implement a solution that is detailed in Figure 12.2:
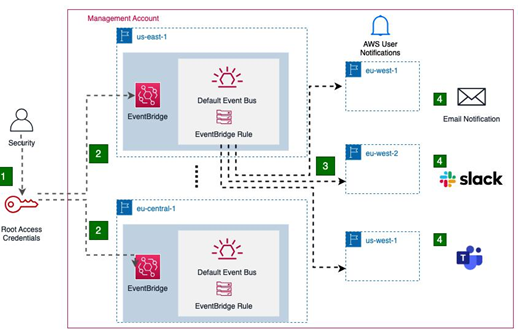
Figure 12.2: Monitoring usage of security break-glass users
Let’s look at this in a bit more detail, as follows:
- During events of security breaches involving the IdP or outages of the service itself, security team members might have to invoke the break-glass process by using the IAM user credentials configured in the AWS management account.
- The user login results in the creation of an event in the EventBridge service, in the region where the user logged in.
- To track these events, one can leverage the AWS User Notifications service, which handles the lifecycle management of event tracking and forwarding in the target regions of the management account. To track the event that defines console login for the break-glass user, one can configure the IAM user Amazon Resource Name (ARN) in the User Notifications service. For example, to track a user named break-glass-1, one can use the following ARN in the service: arn:aws:iam:::user/break-glass-1. The event is then forwarded to one of the three aggregator regions that are also managed and configured by the service.
- A notification is sent out on the configured destination platform, which as of writing this chapter can be MS Teams, Slack, or email.
Building resilient and highly available systems
The main focus of the Reliability pillar within the AWS Well-Architected Framework is to create systems capable of automatically recovering from infrastructure or service interruptions and seamlessly adjusting to evolving conditions. The ultimate objective is to guarantee applications’ high availability (HA), resilience, and maintainability, by keeping downtime at a minimum and delivering a reliable and uninterrupted experience for end users.
Let’s discuss some best practices that simplify the achievement of these objectives when deploying workloads on AWS.
Best practices for building reliable applications on AWS
Through the implementation of automated recovery processes, rigorous testing, horizontal scaling, and efficient change management, organizations can ensure their applications remain resilient and provide a consistent experience for users. It’s important to remember that every single component in your AWS architecture can fail; therefore, you need to at least have a plan in place that outlines the course of action when unforeseen events happen.
Automatically recovering workloads from failures
A good monitoring and alerting strategy depends on business KPIs instead of technical thresholds. Depending on the nature of your application, you can start with what good looks like, and derive business KPIs from that, which can then be monitored. For example, an e-commerce shop could watch for delays in shopping cart processing time instead of blindly looking at the CPU crossing 90% usage thresholds, as the latter does not help you measure the business outcome.
Scaling your workloads by leveraging AWS availability constructs
All AWS regions are composed of three or more Availability Zones (AZs), which by themselves are a collection of multiple data centers. When architecting systems in the cloud, it’s important to spread your resources throughout these discrete locations and horizontally scale your systems. Also, resource constraints are usually scoped to a particular AZ. So, distributing your applications across multiple AZs offers additional benefits of higher availability and uniform resource spread, eventually improving your application uptime and reliability.