
Static provisioning of resources in AWS will not offer you the elasticity to automatically scale up or scale down based on changing demands. With features such as Elastic Compute Cloud (EC2) Auto Scaling or serverless capabilities of AWS services, you can ensure that reasonable demand needs are met automatically, without any manual intervention or interruptions to the application’s availability.
An e-commerce shop might have demand spikes during specific times of the year that can be easily met with such practices, for example. On the other hand, there should also be controls that block automatic scale-up beyond certain thresholds, which might instead be representative of service availability attacks such as Distributed Denial-of-Service (DDoS) attacks. These measures avoid any unexpected cost burden and misuse of services.
Leveraging automation for any changes to the infrastructure or application
Completely avoiding manual interventions for any changes to be rolled out in the application or infrastructure is an important step in the direction of building reliable systems. When operating in AWS, you might be deploying resources across multiple accounts, regions, and AZs. This necessitates the need for automation even further as the chances of configuration drift increase when these changes are rolled out manually. Secondly, any modern application these days is composed of several services that can only be efficiently managed when modifications are coordinated and rolled out using code that has been tested in another environment beforehand.
Such approaches make the process of rolling out changes at an infrastructure or application level more reliable, visible, and trackable, additionally allowing you to focus on differentiated value creation.
Most companies architect their cloud applications for failure handling but rarely test these scenarios in practice, which results in a lack of understanding of how these applications actually behave when unforeseen situations happen. Let’s look at a test setup demonstrating how one could simulate outages across different components of a typical web application stack.
Injecting failures with AWS Fault Injection Simulator
Simulating failures across different application components can be carried out with manual actions in the console, automated test scripts, or by leveraging services such as AWS Fault Injection Simulator (FIS). FIS provides out-of-the-box integrations with services such as EC2, Relational Database Service (RDS), Elastic Kubernetes Service (EKS), and so on to simulate operational events. Thesesimulations surface software behaviors that are otherwise only experienced during real outage events.
Have a look at the following diagram:
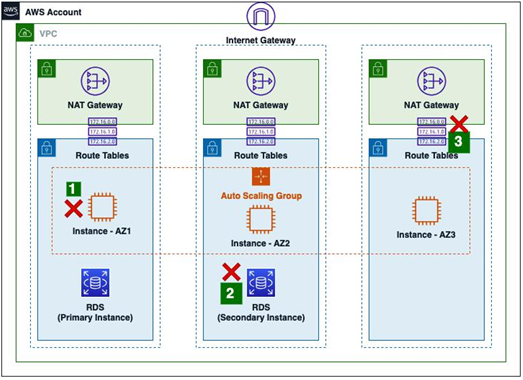
Figure 12.3: Simulating failures with AWS Fault Injection Simulator
For a typical web application fronted by a load balancer and application code deployed in EC2 instances that persist data in a Multi-AZ RDS database, one could follow these steps for failure injection, using the FIS service:
- Random EC2 instances in the architecture are shut down, and the application, as a whole, is still expected to work fine as incoming requests should be distributed to the remaining EC2 instances by the load balancer. During these resiliency tests, one starts with a hypothesis on what they expect to happen when a failure occurs and confirms that hypothesis by actually carrying out the corresponding action. To continuously check the response of an application API during this time, one could leverage the AWS CloudWatch Synthetics service, which repeatedly tests an endpoint, generating traffic just like a regular end user.
- After the compute instances’ failure simulations are validated, one can move ahead with database-level resiliency tests. The FIS service supports restarting the active database instance from an RDS cluster, in a Multi-AZ setup. This should mimic the scenario where a particular AZ is affected, resulting in a trigger of the database failover process.
- Finally, after the failures of individual resources and their corresponding impacts have been analyzed, one can proceed with an AZ-wide outage. This is commonly achieved bydetaching NACLs from the subnets in the second or third AZ, as shown by point 3 in Figure 12.3. This will make all resources in that AZ unreachable, and the tests can validate how the application responds to this situation.
Using these resiliency test procedures gives software teams confidence by increasing awareness of unknown limitations of the software application architecture, or the expectation from AWS cloud services. It’s advisable to execute these tests regularly so that operational runbooks and procedures can also evolve over time, leading to a more reliable cloud presence.